Spatial Regression
May 30, 2019
During the past couple of years I have been giving an introduction seminar to Spatial Regression using R. I have decided to put part of the seminar's material here.
Outline
- Introduction
- About the code used
- Linear Regression
- Trend Surface
- Covariance Functions
- Geostatistical Process
- References
1. Introduction
"Everything is related to everything, but near things are more related than distant things" [Waldo Tobler]
This law of Geography can be translated to the language of Statistics as: things nearby are more alike and thus we can expect them to be positively correlated. The core idea behind Spatial Statistics is to understand an characterize this spatial dependence that is observed in different processes, for example: amount of rainfall, global temperature, air pollution, etc.
Spatial dependence, as a concept, started to be formally addressed by statisticians at the beginning of the XX century (Fisher, 1935). However, it was until the second half of the century when Matheron (1962, 1963) and Gandin (1963) developed a best linear unbiased predictor (blup) for spatial modeling. Kriging, as the predictor is known, became the standard modeling approach of continuous spatial variation.
Geostatistical methods have traditionally been related to data observed at a set of spatial locations indexed in a continuous space. This is as opposed to lattice methods and point pattern methods. The former related to data observed on a fixed set locations and the latter used for data associated to a point process. Diggle et al. (2013) consider that distinctions based on data formats are not always appropriate. They argue that the main theoretical distinction within spatial statistics is the continuity or non-continuity of the process being modeled. The model-based approach (Diggle et al., 1998) has become the current paradigm for modelling variability and quantifying uncertainty: a hierarchical thinking that explicitly assumes a stochastic model, but also acknowledges a different uncertainty in the data and in the parameters of the process (Cressie and Wikle, 2011).
2. About the Code Used
Along the discussion we will show some interactive examples. We will use some auxiliary code for running these examples, which will be available for everybody to download from this repository. The following R packages need to be preinstalled for the code of this session to work:
MASS
pracma
GPFDA
RandomFields
caret
rstan
Rcpp
ggplot2
viridis
In general, we will call the methods of the packages as:
package_name::method_name()This is as opposed to loading the package and calling the method directly:
library(package_name)
method_name()
We will do this so that it is explicit which method belongs to which package. The exceptions to this rule will be ggplo2 and Rccp. The former because otherwise notation becomes too long and less readable when making plots, and the latter because otherwise we will run into problems when calling rstan.
The command below will load ggplot, Rcpp and the auxiliary code needed for the session.
library(ggplot2)
library(Rcpp)
source("r_code/auxiliary_functions.R")
3. Linear Regression
As a first step it will be convenient to have a brief recap on linear regression. Let \( \{ y_i, x_{i1}, \ldots, x_{ip} \}_{i=1}^n \) be a set of dependent and explanatory variables. In Ordinary Least Squares we usually want to estimate the parameters \( \{\beta_j\}_{j=0}^{p} \) that best fit the model
\( y_i = \beta_0 + \beta_1 x_{i1} + \ldots + \beta_j x_{ip} + \epsilon_i\) for \(i = 1, \ldots, n.\)
where \( \epsilon_i \) a Gaussian random variable with mean zero. The parameters chosen are the ones that generate the hyperplane that is closest on average to all the points \( x_{ij} \).
## Example
# Generate some toy data
reg_data <- lm_data(seed=0)
reg_data$type <- 'observed'
# Fit linear model
model1 <- lm(y ~ x, data=reg_data)
# Predictions
x_linspace <- seq(.5, 2.5 * pi, length.out=100)
to_append <- data.frame(x=x_linspace, y=predict(model1, newdata=data.frame(x=x_linspace)), type='order_1')
reg_data <- rbind(reg_data, to_append)
# Plot results
ggplot(data=subset(reg_data, type=='observed'), aes(x, y)) +
geom_point(col="steelblue", size=2) +
geom_line(data=subset(reg_data, type=='order_1'), col="red") +
ggtitle(label = "Linear Regression Example") +
theme_minimal()
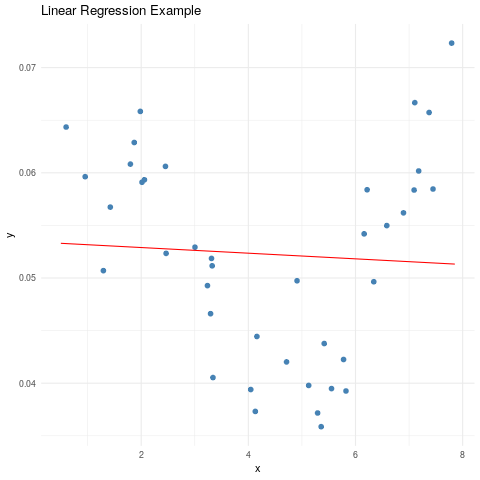
Sometimes (almost every time) a straight line is not enough to explain the relationship between \(x_i\) and \(y_i\). This usually makes us start thinking of some polynomial regression that is more adequate. For example:
Order 2: \( y_i = \beta_0 + \beta_1 x_i + \beta_2 x_i^2 + \epsilon_i \)
Order 3: \( y_i = \beta_0 + \beta_1 x_i + \beta_2 x_i^2 + \beta_3 x_i^3 + \epsilon_i \)
n_poly <- 4
poly_data <- reg_data
for (i in 2:n_poly) {
new_dataset <- subset(reg_data, type=='observed')[,-c(3)]
new_linspace <- data.frame(x=x_linspace)
for (j in 2:i) {
new_dataset[paste0("x", j)] <- new_dataset$x^j
new_linspace[paste0("x", j)] <- new_linspace$x^j
}
m <- lm(y ~ ., data = new_dataset)
to_append <- data.frame(x=x_linspace,
y=predict(m, newdata=new_linspace),
type=paste("order", i, sep="_"))
poly_data <- rbind(poly_data, to_append)
}
# Plot results
ggplot(data=subset(poly_data, type=='observed'), aes(x, y)) +
geom_point(col="steelblue", size=2) +
geom_line(data=subset(poly_data, type!='observed'), aes(color=type)) +
ggtitle(label = "Polynomial Regression Example") +
theme_minimal()
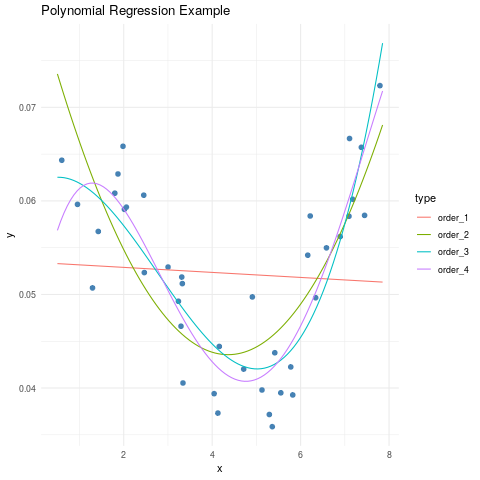
4. Trend Surface
Linear regression models can be used to summarize the variation in spatial patterns. A trend surface of order \(n\) can be estimated by applying a regression model using the spatial coordinates as the independent variables. For example, let the longitude and latitude coordinates be defined as \(x_{i1}\) and \(x_{i2}\) respectively, then we can describe the following trend surfaces:
Order 1: \( y_i = \beta_0 + \beta_1 x_{i1} + \beta_2 x_{i2} + \beta_3 x_{i1} x_{i2} + \epsilon_i\)
Order 2: \( y_i = \beta_0 + \beta_1 x_{i1} + \beta_2 x_{i2} + \beta_3 x_{i1} x_{i2} + \beta_4 x_{i1}^2 + \beta_5 x_{i2}^2 + \epsilon_i \)
Note that we are also adding the product \(x_{i1} x_{i2}\). This is a term that accounts for the interactions.
Having a trend across the surface seems like a good idea. However we will see that it is not the best approach.
First Now, we will make a new toy dataset to see how this approach works.
Imagine that we have a plot of \(400m \times 400m\) where we want to study a specific property of the soil, we will call it soiliness. We pick different locations at random and take measurements of soiliness.
## Soil example
spatial_reg <- soil_data(n_peaks=2, n_data = 150, seed=0)
head(spatial_reg)
ggplot(spatial_reg, aes(lng, lat)) +
geom_point(aes(col=soiliness), size=2.5) +
viridis::scale_color_viridis(option="plasma") +
ggtitle("Clustered Spatial Data") +
theme_minimal()
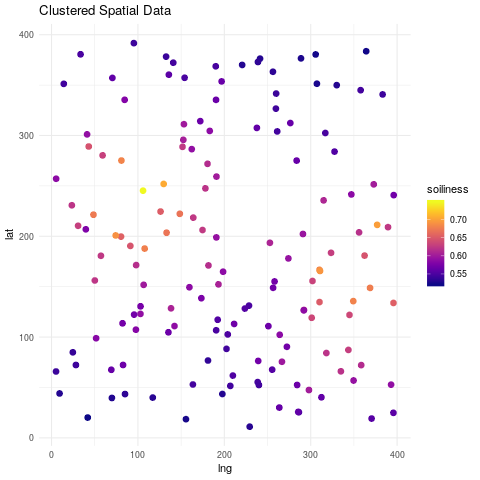
Below we show the resulting fitted surfaces.
# Fit a model with a trend of order 1
surf_order1 <- lm(soiliness ~ lng * lat, data=spatial_reg)
# Fit a model with a trend of order 2
surf_order2 <- lm(soiliness ~ lng * lat + I(lng^2) + I(lat^2), data=spatial_reg)
# Grid for predictions
surf_grid <- as.data.frame(make_grid(size = 20))
surf_grid$surface_o1 <- predict(surf_order1, newdata=surf_grid)
surf_grid$surface_o2 <- predict(surf_order2, newdata=surf_grid)
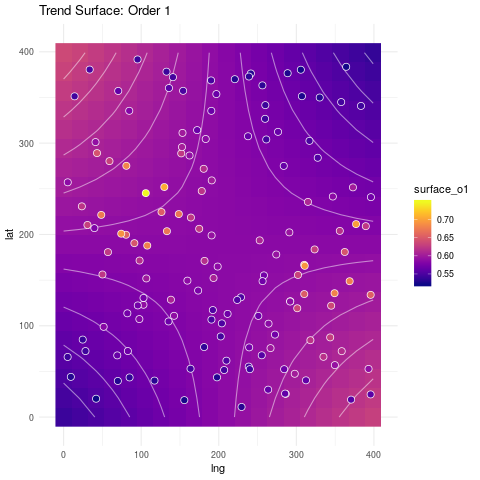
ggplot(surf_grid, aes(lng, lat)) +
geom_raster(aes(fill=surface_o1)) +
geom_contour(aes(z=surface_o1), col="white", linetype=1, alpha=.5) +
geom_point(data=spatial_reg, aes(fill=soiliness), colour="white", pch=21, size=3) +
viridis::scale_fill_viridis(option="plasma", na.value="darkblue") +
ggtitle("Trend Surface: Order 1") +
theme_minimal()
ggplot(surf_grid, aes(lng, lat)) +
geom_raster(aes(fill=surface_o2)) +
geom_contour(aes(z=surface_o2), col="white", linetype=1, alpha=.5) +
geom_point(data=spatial_reg, aes(fill=soiliness), colour="white", pch=21, size=3) +
ggtitle("Trend Surface Order 2") +
viridis::scale_fill_viridis(option="plasma", na.value="darkblue") +
theme_minimal()
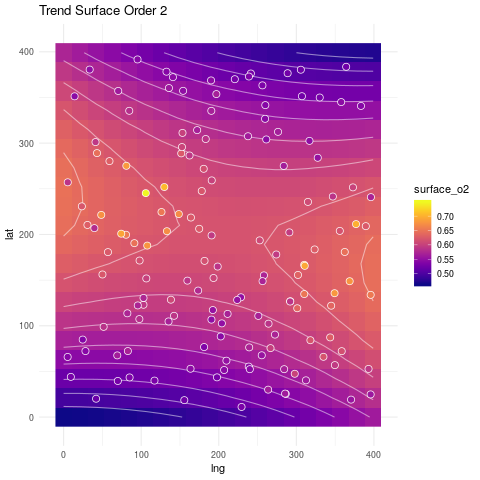
Can we get a fit that resembles more what the data looks like? The answer is yes, as we will see next.
5. Covariance Functions
What we need from a model to produce a better fit is that it works under the assumption that points which are close are likely to have similar target values (soiliness in this case). In other words, we expect the observed target values to change together across space.
When want to measure how much two variables change together, we use the covariance function. Under the right assumptions, we can also use the covariance function to describe the similarity of the observed values based on their location.
Covariance function: A function \(K: S \times S → R\) is a covariance function if it is continuous, symmetric and positive definite.
For example, assume that \(S \subset R\) and that \(r = ||(x_{i1},x_{i2})^\top - (x_{j1},x_{j2})^\top ||\).
The exponentiated quadratic or RBF covariance function is defined as
\(K(x_i, x_j) = \sigma^2 exp \left( \frac{- r^2 }{ 2 \ell^2} \right) \), for some positive parameters \(\sigma\) and \(\ell\).
The rational quadratic covariance function is defined as
\(K(x_i, x_j) = \sigma^2 \left( 1 + \frac{ r^2 }{ 2 \alpha \ell^2} \right) ^{-\alpha}\) for some positive parameters \(\sigma\), \(\alpha\) and \(\ell\).
The power exponential covariance function is defined as
\(K(x_i, x_j) = \sigma^2 exp\left( - \left(\frac{ r }{ \ell} \right) ^{\gamma} \right)\) for some positive parameters \(\sigma\) and \(\ell\).
The election of which covariance function to use depends on our assumptions about the change in the association between the points across space (eg., the speed of decay).
## Code to plot covariance functions
x_0 <- as.matrix(0, nrow=1, ncol=1)
x_linspace <- as.matrix(seq(-8, 8, length.out = 100), ncol=1)
kval <- c(as.numeric(rbf(x_0, x_linspace, sigma=1, lengthscale=1)),
as.numeric(rqd(x_0, x_linspace, sigma=1, lengthscale=1, alpha=1)),
as.numeric(pow(x_0, x_linspace, sigma=1, lengthscale=1, gamma=1)))
kname <- c(rep("exp_quad", 100), rep("rat_quad", 100), rep("pow_exp", 100))
covdf <- data.frame(x=rep(x_linspace, 3), k=kval, covariance= kname)
ggplot(covdf, aes(x, k)) + geom_line(aes(col=covariance)) +
ggtitle("Different Covariance Functions") +
theme_minimal()
Here is an example in 2 dimensions to illustrate the concept of the covariance function. Suppose we have 10 locations randomly selected in our in our \(400m \times 400m\) plot.
## Generate 10 data points
xx <- random_points_ordered(n_points = 10, seed=0)
ggplot(as.data.frame(xx), aes(lng, lat)) +
geom_point(col="steelblue", size=2.5) +
theme_minimal()
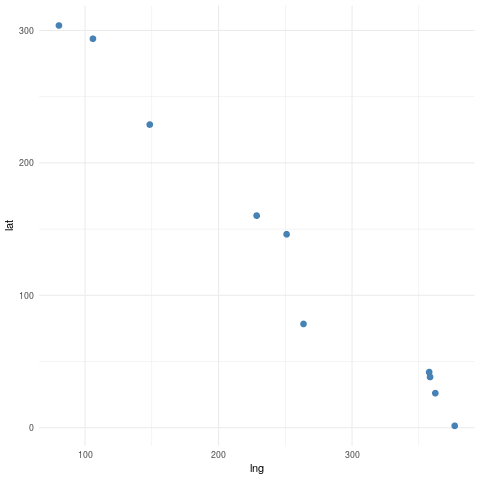
Based on the pairwise distances between the points, the resulting covariance matrix under a Rational Quadratic model is the following.
## Spatial covariance between points
K <- rqd(xx, xx, lengthscale=20, alpha=2)
kdf <- data.frame(k = as.vector(K),
point_i = factor(rep(10:1, 10)),
point_j = factor(sort(rep(1:10, 10), decreasing=TRUE)))
ggplot(kdf, aes(point_j, point_i)) +
geom_raster(aes(fill=k)) +
viridis::scale_fill_viridis(option="plasma") +
ggtitle("Covariance Matrix") +
scale_y_discrete(limits=rev(levels(kdf$point_i))) +
theme_minimal()
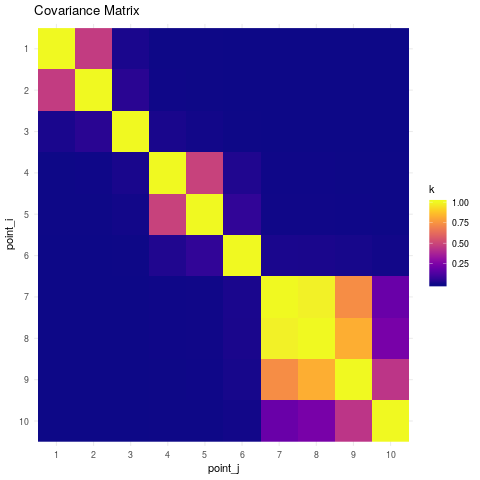
6. Geostatistical Process
Now that we have discussed how the covariance function can help describe properties we observe in our data, we can discuss how to incorporate this ideas into a model.
Before, we mentioned that a surface trend could be modeled as
\(y_i = \beta_0 + \beta_1 x_{i1} + \beta_2 x_{i2} + \beta_3 x_{i1} x_{i2} + \epsilon_i\).
Instead we will model our data as
\(y_i = f_i(x_i) + \epsilon_i\), where \(f = (f_1, \ldots, f_n)^\top\) is a multivariate normal distribution.
Why? A Gaussian distribution is completely defined by its first two moments. Moreover, a centered Gaussian distribution is uniquely defined by its covariance. This means that in our new model, for every \(y_i\) we will have now an underlying Gaussian variable \(f_i\) with the property that all \({f_i}\) have a spatial dependence structure given by \(K(x_i, x_j)\).
Gaussian process: A Gaussian process is a collection of random variables, any finite number of which have a joint Gaussian distribution.
We denote a Gaussian process with mean function $m$ and covariance function \(K\) as \(f(x) \sim \mathcal{GP}\big(m(x), K(x, x)\big)\).
While in the linear regression model we estimate the $\beta$ parameters, here we estimate the values of \(f_i\) at the locations \(x_i\). We have to be aware that \(f_i\) are not parameters in the sense of classical statistics, they are random variables and we will handle them under a Bayesian approach. Given the observed data \(\{x, y\}\), the posterior distribution of \(f\) is given by:
\(p(f|y,x) \propto p(y|f,x) p(f|x)\)
We will assume for the moment that \(m(x)=0\). This is a common assumption that doesn't reduce the flexibility of the method, but simplifies handling it. Notice \(\epsilon = (\epsilon_1, \ldots, \epsilon_n)^\top\) is joint Gaussian with mean zero and Covariance matrix \(I \sigma^2_\epsilon\). Thus \(y \sim N(0, K(x,x) + I\sigma^2_\epsilon)\). Then it turns out that \(f_\ast|y,x\) (posterior of \(f\) at new locations \(x_\ast\)) is multivariate Gaussian with mean
\(E(f_\ast|y,x) = K(x_\ast,x)(K(x,x) + I\sigma^2_\epsilon)^{-1}y\)
and covariance
\(Var(f_\ast|y,x) =K(x_\ast,x_\ast) - K(x_\ast,x)(K + I\sigma^2_\epsilon)^{-1} K(x, x_\ast)\).
Usually, we want to predict new realizations of \(y_\ast\), instead of \(f_\ast\). The predictive values of \(y_\ast\), given the observations are computed as
\(p(y_\ast|y,x) = \int p(y_\ast |f_\ast) p(f_\ast|y,x) df_\ast\).
In this case, since \(y\) is just a noisy version of \(f\) where the noise is Gaussian with zero mean, it turns out that
\(E(y_\ast|y,x) = K(x_\ast,x)(K(x,x) + I\sigma^2_\epsilon)^{-1}y\)
and
\(Var(y_\ast|y,x) =K(x_\ast,x_\ast) - K(x_\ast,x)(K + I\sigma^2_\epsilon)^{-1} K(x, x_\ast) + I\sigma^2_\epsilon\).
Going back to our soil example, this is how a Gaussian process regression fit looks like.
# For the moment we will assume that the following quantities are known
rbf_sigma <- 20
rbf_lengthscale <- 25
epsilon_sigma <- 10
# These are the locations of the train set and predictions
X <- as.matrix(spatial_reg[, c("lng", "lat")])
X_star <- as.matrix(surf_grid[, c("lng", "lat")])
# Output value
Y <- as.matrix(spatial_reg$soiliness)
# Fit a Gaussian process
gp_fit <- gp_regression_rbf(X, Y, X_star, k_var=rbf_sigma^2, k_len=rbf_lengthscale, noise_var=epsilon_sigma^2)
surf_grid$surface_gp_mean <- gp_fit$gp_mean
surf_grid$surface_gp_var <- gp_fit$gp_var
ggplot(surf_grid, aes(lng, lat)) +
geom_raster(aes(fill=surface_gp_mean)) +
geom_contour(aes(z=surface_gp_mean), col="white", linetype=1, alpha=.5) +
viridis::scale_fill_viridis(option="plasma", na.value="darkblue") +
ggtitle("Gaussian Process - Predictive Mean") +
theme_minimal()
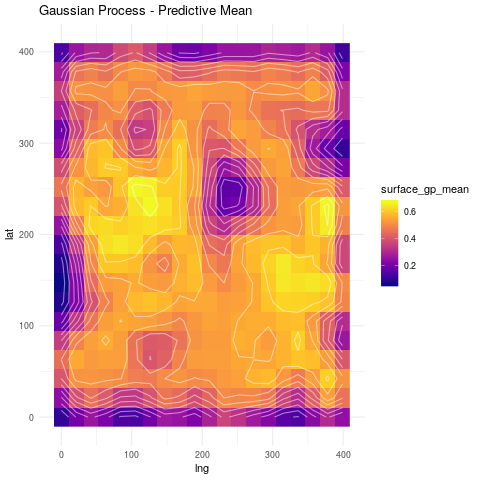
ggplot(surf_grid, aes(lng, lat)) +
geom_raster(aes(fill=surface_gp_var)) +
geom_contour(aes(z=surface_gp_var), col="white", linetype=1, alpha=.5) +
geom_point(data=spatial_reg, colour="white", pch=21, size=3) +
viridis::scale_fill_viridis(option="plasma", na.value="darkblue") +
ggtitle("Gaussian Process - Predictive Variance") +
theme_minimal()
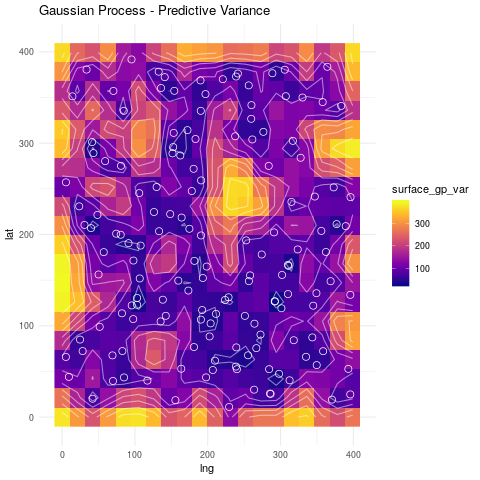
Notice that the regions with no points have higher variance, while the regions with many points concentrated have a low variance. Remember that in the Bayesian approach, the variance is a measure of uncertainty. Thus, we are more uncertain about the process when there are no observations nearby and become more certain the more observations we have.
Since the Gaussian process is defined by its mean and covariance, these are usually the parameters we are mostly interested in estimating. However these are not the only parameters of the model. As we discussed before, the covariance functions have different parameters associated, for example \(\sigma\), \(\ell\) or \(\gamma\). We usually refer to them as hyperparameters.
The values of the hyperparameters can also be chosen based on the data. While the optimal solutions for the posterior mean and variance have a nice and simple analytical expression, as we saw above, estimating optimal values for the hyperparamters is not that straightforward.
When taking into account the hyperparameters the posterior distribution of \(f\) should be written as
\(p(f|y,x,\theta) \propto p(y|f,\theta) p(f|x, \theta) \).
The normalizing constant of the expression above is given by
\(p(y|x,\theta) = \int p(y|f,\theta) p(f|x, \theta) df\),
which can be used to calculate the posterior distribution of \(\theta\)
\(p(\theta|y,x) \propto p(y|x,\theta) p(\theta)\),
with normalizing constant
\(p(y|x) = \int p(y|x,\theta) p(\theta) d\theta\).
Solving the integral above can be a hard task, and we can rely on Markov Chain Monte Carlo methods to do so. An alternative is to find the value of \(\theta\) that maximizes the marginal likelihood \(p(y|x,\theta)\). Here the term marginal refers to the fact that \(p(y|x,\theta)\) is computed after marginalizing the latent function \(f\). By following this approach we are choosing the combination of \(\theta\) values where the likelihood of the data observed \(y\) is the highest. This approach is know as Maximum Likelihood type II.
Below is an example of how to use Monte Carlo methods to estimate the posterior distribution of the hyperparameters using RStan.
fit_hyper <- rstan::stan(file="stan_code/gp_gaussian_fit_hyper.stan",
data=list(n_data = nrow(spatial_reg),
n_dim = 2,
y_data = spatial_reg$soiliness,
X_data = spatial_reg[, c("lng", "lat")],
mu_data = rep(0, nrow(spatial_reg))),
pars = c("noise_var", "cov_var", "cov_length"),
warmup = 1000, iter = 5000, chains = 4,
verbose = FALSE, seed=123)
hyper_params <- rstan::extract(fit_hyper)
noise_var <- mean(cbind(hyper_params$noise_var))
cov_var <- mean(cbind(hyper_params$cov_var))
cov_length <- colMeans(cbind(hyper_params$cov_length))
We will use the mean values of the samples generated as point estimates and show the predicted surface of the Gaussian process.
Note: Our stan implementation considers a different lengthscale for each dimension in X, while our RBF function considers a single parameter. For the moment we will use as lengthscale value the average of both lenghtscale parameters.
# Fit a Gaussian process
gp_fit_stan <- gp_regression_rbf(X, Y, X_star, k_var=cov_var, k_len=mean(cov_length), noise_var=noise_var)
surf_grid$surface_gp_mean_stan <- gp_fit_stan$gp_mean
surf_grid$surface_gp_var_stan <- gp_fit_stan$gp_var
# Plot predictive mean
ggplot(surf_grid, aes(lng, lat)) +
geom_raster(aes(fill=surface_gp_mean_stan)) +
geom_contour(aes(z=surface_gp_mean_stan), col="white", linetype=1, alpha=.5) +
geom_point(data=spatial_reg, aes(fill=soiliness), colour="white", pch=21, size=3) +
viridis::scale_fill_viridis(option="plasma", na.value="darkblue") +
ggtitle("Gaussian Process - Predictive Mean") +
theme_minimal()
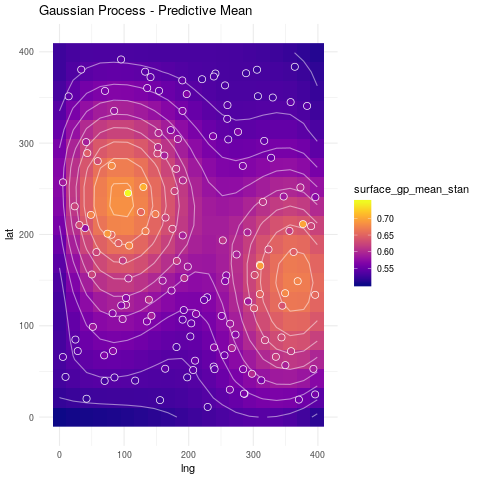
So far all the discussion has been around spatial location. _What about additional information we may have?_. We can have different approaches to include it.
For example, we can define a model as follows
\(y_i = \beta_0 + \beta_1 x_{i1} + \ldots + \beta_q x_{iq} + f(x_{is}) + \epsilon_i\), where
\(\{x_{ij}\}_{j=1}^{q}\) are different covariantes and \(x_{is}\) are spatial coordinates.
Also \(f(x_{is})\) does not have to be constrained to a 2-dimensional space. We can use \(f(x^\ast_i)\), where \(x^\ast_i\) is a vector that includes the spatial locations and other data features. In such a case, these features will also have a non-linear effect. For example, if the input vector contains spatial location and a temporal reference, \(x^\ast = (x^{(s)}, x^{(t)})\), a covariance function for a space-time process can be defined as:
\(K(x^\ast_i, x^\ast_j) = \sigma^2 exp \left( -\frac{||x^{(s)}_i - x^{(s)}_j||^2 }{ 2 \ell^2_s} - \frac{||x^{(t)}_i - x^{(t)}_j||^2 }{ 2 \ell^2_t} \right)\).
Note that the expression above, is in fact the product of two covariance functions:
\(K(x^\ast_i, x^\ast_j) = \sigma^2 exp \left( -\frac{||x^{(s)}_i - x^{(s)}_j||^2 }{ 2 \ell^2_s} \right) exp \left(- \frac{||x^{(t)}_i - x^{(t)}_j||^2 }{ 2 \ell^2_t} \right)\).
It is also possible to use sums of covariance functions to have additive effects of the form
\(y_i = f_1(x^\ast_i) + f_2(x^\ast_i) + \epsilon_i\).
7. References
- Cressie, N. and Wikle, C. K. (2011). Statistics for spatio-temporal data. John Wiley & Sons.
- Diggle, P. J., Moraga, P., Rowlingson, B., Taylor, B. M., et al. (2013). Spatial and spatio-temporal log-Gaussian Cox processes: Extending the geostatistical paradigm. Statistical Science, 28(4):542–563.
- Diggle, P. J., Tawn, J., and Moyeed, R. (1998). Model-based geostatistics. Journal of the Royal Statistical Society: Series C (Applied Statistics), 47(3):299–350.
- Fisher, R. A. (1935). The design of experiments. Oliver & Boyd.
- Gandin, L. S. (1963). Ob“ektivnyi analiz meteorologicheskikh polei. Gidrometeologicheskoe Izdatel’stvo, Leningrad. Translation (1965): Objective analysis of meteorological fields. Israel Program for Scientific Translations, Jerusalem.
- Matheron, G. (1962). Traité de géostatistique appliquée, tome I. Mémoires du Bureau de Recherche Géologiques et Minières, No. 14. Editions Technip, Paris.
- Matheron, G. (1963). Traité de géostatistique appliquée, tome II: le krigeage. Mémoires du Bureau de Recherche Géologiques et Minières, No. 24. Editions Bureau de Recherche Géologiques et Minières, Paris.
- Rasmussen, Carl Edward. Gaussian processes in machine learning. Advanced lectures on machine learning. Springer, Berlin, Heidelberg, 2004. 63-71.